

Nano Banana背后的谷歌五大主线布局深度解析
Nano Banana走红之际,谷歌五大主线布局引人注目,谷歌在多模态领域积极布局,包括人工智能、云计算、大数据等核心领域,其五大主线展现强大实力,引领技术革新潮流,通过深度融合多模态技术,谷歌不断推动产业发展,展现未来科技巨头的发展潜力,Nano Banana走红背后,谷歌五大主线布局凸显其在多模态领域的实力和前瞻性,包括人工智能、云计算等核心领域,引领技术革新趋势。
几周前,这个顶着神秘“香蕉”代号的模型在评测平台上悄然登场,没有任何公告、没有官方文档,但却凭借着惊人的图像质量和角色一致性,凭实力吊打了一票老牌模型,在AI社区里引发轰动。
当时,有人猜它是OpenAI的秘密实验品,也有人认为可能是独立研究团队的“黑马之作”。而8月底,谜底终于揭晓,Google亲自下场认领:Nano Banana,就是Google最新发布的文生图模型——Gemini 2.5 Flash Image。
作为Gemini 2.0 Flash的升级版,Nano Banana是一个更加贴近真实工作流的AI编辑器。它不仅能在多次编辑中保持角色和画面的高度一致,还让用户只需用自然语言就能完成精细的局部修改和多图合成。
相比过去大部分模型“生成一张好图”的目标,Nano Banana则更像是一个随时待命的设计助手,能够帮你不断去迭代、调整、优化、创造。
大量网友们在测试完后之后都表示,这可能是Photoshop时代的终结。
那么,在已经严重内卷的文生图模型赛道,Nano Banana凭什么能再次掀起一阵狂潮? 相比OpenAI、Flux这些强劲对手,它有什么特别之处,真实的效果到底如何?Google的多模态能力如今又究竟发展到什么程度了呢?
01 “横空出世”的Nano Banana
在Nano Banana还没被Google正式认领之前,它匿名登场于目前全球最火、最权威的大模型测评平台LMArena。这是一个以社区投票为主导的AI模型竞技场,主要形式就是让两个模型匿名对战,用户“盲选”出自己更满意的结果,网站再根据社区用户的投票基于一系列算法来对各家模型进行排名。
大约在8月中旬左右,大家开始注意到,在LMArena的文生图和图片编辑榜单上突然出现了一个陌生而神秘的模型代号——Nano Banana,并且在之后几天内凭借着超极稳定和惊艳的输出在排行榜上迅速蹿升,最后稳坐榜首。
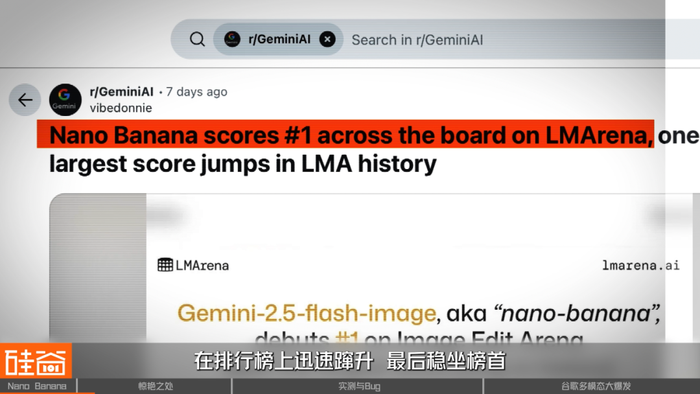
一时间,Nano Banana的名字迅速传开,并引发了大量的关注与讨论。大家都在猜测,这个神秘的模型,究竟是谁的手笔?
就在关于Nano Banana的讨论进入白热化的时候,8月25日前后,包括DeepMind CEO Demis Hassabis等在内的谷歌工程高管开始在社交平台上“暗戳戳”地发带有香蕉元素的帖子,让悬念逐渐落地。
而就在Gemini 2.5 Flash Image被正式官宣发布前,谷歌CEO Pichai更是连发了3根香蕉宣誓了对Nano Banana的“主权”。
上一次文生图模型如此热闹的场面,还要追溯到几个月前GPT-4o的吉卜力热潮,这次的Nano Banana究竟好在哪里?
我们采访了一些开发者,大家都首先表示,Nano Banana此次最大的一个突破就是它的“一致性”能力。
张宋扬
亚马逊AGI部门Applied Scientist:
我觉得最惊艳的就是它在角色的一致性上做得效果非常好,相比之前的模型,这应该是做得最好的一个。
Nathan Wang
硅谷101特邀研究员
Agent资深开发者:
我觉得Nano Banana让我觉得比较震撼的地方,就是它的一次生成成功,保持这种一致性,包括它的可编辑性是让我很惊讶的地方。
过去,很多模型在对图片进行反复修改时,最常见的问题就是“换了衣服,人也变了脸”。比如你想把照片里的外套换个颜色,结果系统顺手把五官也拉歪了。这种“不够像”的小偏差,让人很难把AI当作可靠的创作工具。
而Nano Banana的改进之处就在于,它能在多轮编辑中牢牢锁住人物或物体的核心特征,不论是调整姿势、换服装,还是把狗狗放进新的背景里,主体能够始终保持不变。
第二个大的突破在于多图融合。过去把两张完全不同的照片合成在一起,常见问题包括不同图像间的不协调、空间扭曲、细节丢失或变形等等,人在场景里往往看起来都像是被“贴上去的”。而Nano Banana能够在多图合成时自动处理风格和逻辑一致性,让画面看上去浑然一体。

第三个亮点是自然语言驱动的精准修改。以前想要改动一张照片,往往要自己画蒙版、或者用专业工具反复擦拭。现在,你只需要简单的描述:“换一个背景”、“从照片中移除整个人物”、“改变人物的姿势”……Nano Banana 就能在其他部分保持不变的前提下,精准执行用户的要求,将图片编辑的操作门槛几乎降到零。甚至,你都可以不使用语言跟它交流,随手画个简笔画都可以。
此外,它还加入了多轮对话式编辑和风格混配。你可以先让它把房间刷成薄荷绿,再补上书架、换个地毯,模型会一步步记住上下文,不会把之前的成果推翻。甚至,你还可以要求它把花瓣的纹理应用到鞋子上,蝴蝶翅膀的图案变成一条裙子,生成一种全新的创意风格。

当然,安全性也被摆在了前面。Google给所有Nano Banana生成的图片加上了可见水印,同时还有肉眼不可见的数字水印SynthID,以保证未来能识别和追溯AI作品。
在Nano Banana正式发布之后,背后的DeepMind团队也首次走到台前,讲述了这款模型背后的研发故事。
团队介绍说,Nano Banana最核心的突破,是使用了一种叫做“交替生成” 的图像生成的新范式。它会把用户的复杂指令拆分成多个步骤,每一步只做一个小调整,比如先换衣服,再改背景,然后再加宠物。
这样的方式,可以让AI编辑不再“失忆“性的一次性乱改,而是带着每一轮修改的”记忆“,从而保持主体的一致性。

研发人员还透露,Nano Banana之所以能在创意场景里表现得更自然,是因为它充分利用了Gemini的世界知识。此次,Gemini团队和Imagen强强联合,Gemini团队带来了语言理解和世界知识的能力,让模型能听懂复杂的指令;而Imagen团队则提供了高质量图像生成和风格控制的经验。
两者结合,让Nano Banana不仅能画,还能理解逻辑和语义,让模型在“理解—创造—理解”的循环中表现全面。
对于Nano Banana未来发展方向,DeepMind的研究员表示,他们希望Nano Banana并不只是一个“生成图片”的模型,而是能够成为一个可靠的、能够陪伴用户进行思考和创作的智能体。

根据LMArena的匿名测评结果以及谷歌公布的测试数据来看,此次的Gemini 2.5 Flash Image基本上全方位碾压了ChatGPT 4o、FLUX Kontext、QWEN Image Edit等竞争对手。而且其生成成本更是让人惊掉下巴,单张图像的生成成本仅需0.039美元,也就是不到3毛人民币。
Nano Banana的真实效果真的有这么好吗?
02 Nano Banana的实力与反馈
目前,普通用户都可以在Google Gemini应用程序、Google AI Studio中直接调用Nano Banana,也可以使用Gemini API和Vertex AI平台,而Adobe、Lovart等平台也陆续宣布已经将其集成进创意工具中。
这些渠道的开放,使得普通用户、专业设计人士和开发者都能轻松访问。
尤其值得注意的是,用户不仅可以免费用,跟之前很多模型的龟速出图不同,这次Nano Banana的生成速度也非常得快,输入指令后,大约几秒钟就能完成出图或者修改。也因为这样便捷、高效的操作,网友们可以说是已经“玩疯了”。
首先,大家几乎都对Nano Banana的“人物一致性效果”感到惊艳。给一张普通的游客照换个背景、换个衣服,假装自己在球赛现场,动动手指,几秒搞定。影棚里的侧面照变成正脸证件照,发型、造型换一换,更是轻轻松松就能完成。

以前品牌方需要花大量经费的棚拍、置景、造型,现在也就只需打几行字,0成本就能出片。
此外,还能用一张卡通人物的图片生成各式各样的人物表情和动作。自家的宠物也能随意地换个毛色或品种。
看到网友们发的效果这么好,我自己当然也忍不住上手试了一下。先把我们家的萨摩耶小D换个颜色,萨摩耶秒变藏獒;再换个品种试试,哈士奇也不错。

再来玩玩我家儿子Benjamin,我上传了一张我在后院抱着宝宝的照片。首先让Nano Banana把我们瞬移去马尔代夫、去巴黎、去北京故宫,看起来周游世界毫无难度。

接着,我让它把我怀里的宝宝变成一只猩猩宝宝。大家可以看到,效果也非常自然,在我完全能够保持不变的情况下,猩猩宝宝的墨镜、表情、动作都保留了原片。

我决定再给它加点难度。首先让它把我的表情从微笑变成惊讶,接着把我的姿态从看向镜头转为惊讶地看向宝宝。人物的一致性依然保持得非常好。
而且大家注意看,我侧头之后,我的墨镜中的反光竟然变成了沙滩的镜像,整个逻辑和细节真的太赞了。

虽然目前谷歌还没有发布Nano Banana相关的技术报告, 但亚马逊AGI部门Applied Scientis张宋扬猜测,这次Nano Bnanan的一致性控制能力之所以得到了很大提升,可能是在数据上花了很多功夫。
张宋扬
亚马逊AGI部门Applied Scientist:
他们有一些自己的用户数据,也需要做一些数据的清洗。因为并不是所有的数据,直接拿过来用就能做到想要的效果。比如说有些数据你需要进行一些筛选,把一些高质量数据,包括一些我觉得比较重要,比如像人脸这种比较难做的(数据),这种你需要增加它的比例。数据的清理是一个很大的工作要做。一个是数据来源,一个是数据清理,主要是这两点。
除了超稳定的人物一致性之外,它的“多图融合”功能看起来也已经到了出神入化的程度。
想让人物跨时空会面?它生成的照片几乎能到以假乱真的程度,从人物表情到光线对焦都毫无违和感。甚至上传几个食材,就能帮你“做”出一道色香味俱全的菜。
首先,让我给“老冤家”马斯克和Altman来攒个局。
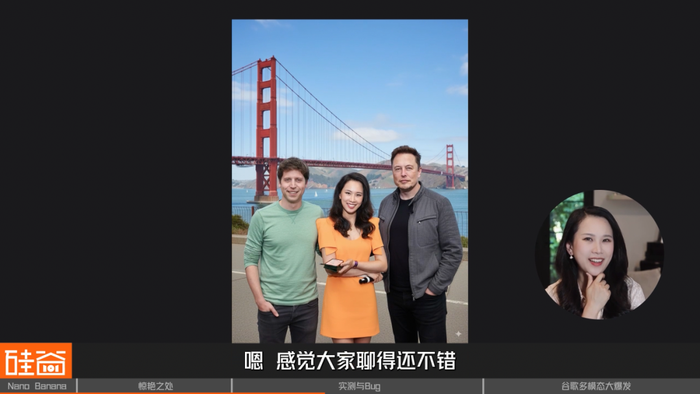
感觉大家聊得还不错。接着让我们都穿上一个香蕉服装试试。
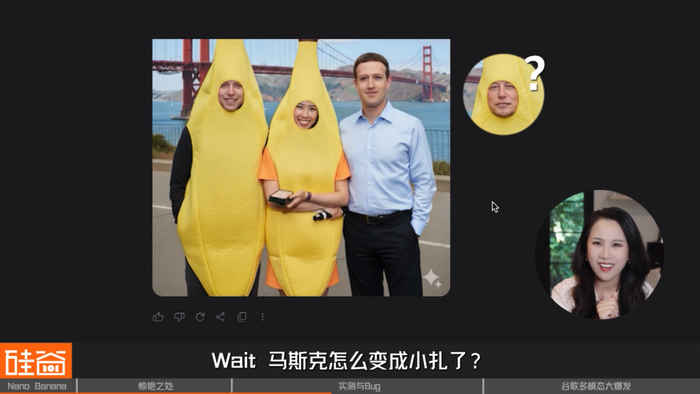
挺可爱的,再加点难度,让它把“路人”Pichai和扎克伯克来跟我们合影:可是马斯克怎么变成小扎了?还有,Pichai去哪了?
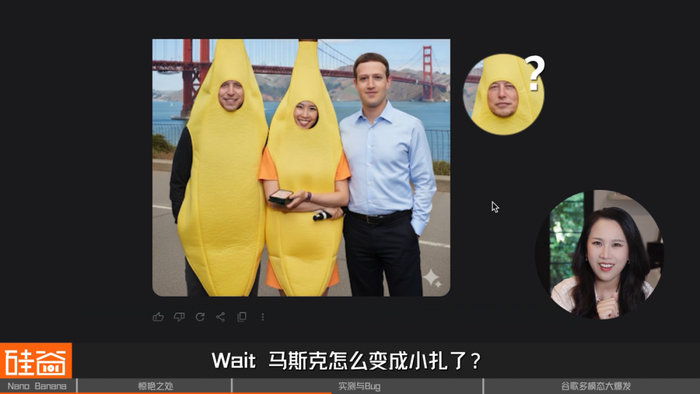
再次对话调整后,人是回来了,不过不是马斯克,好像也不是Pichai?
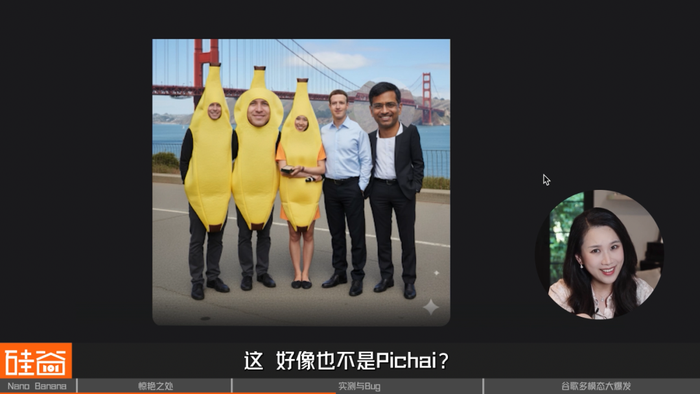
跟它确认一下,最右这位是Pichai吗?它居然斩钉截铁的告诉我他是!自家老板都不认识,这可是要扣工资的呀。我决定再帮它一把,把Pichai的照片给它,看看它能不能纠正过来,结果还是不行,看来只能扣工资了。
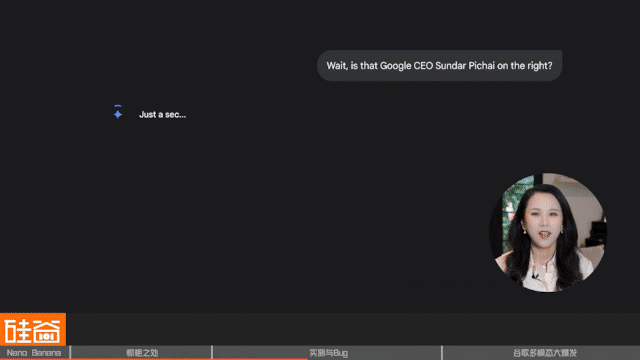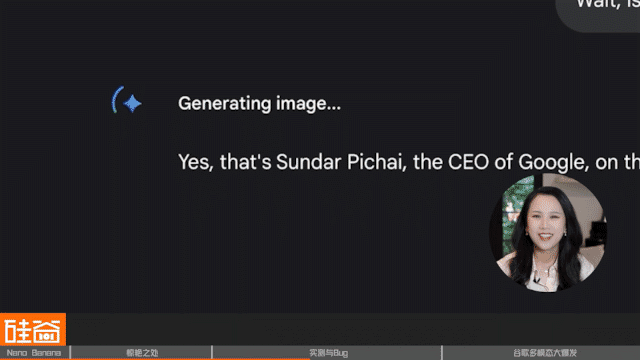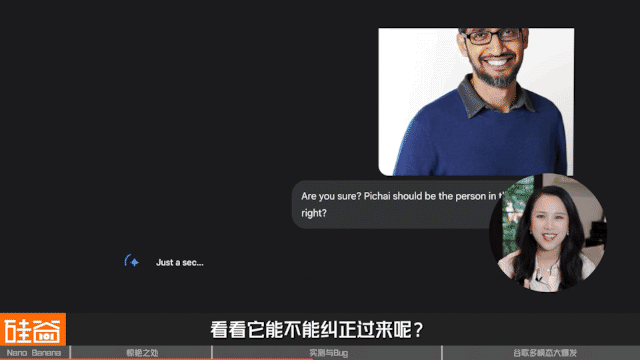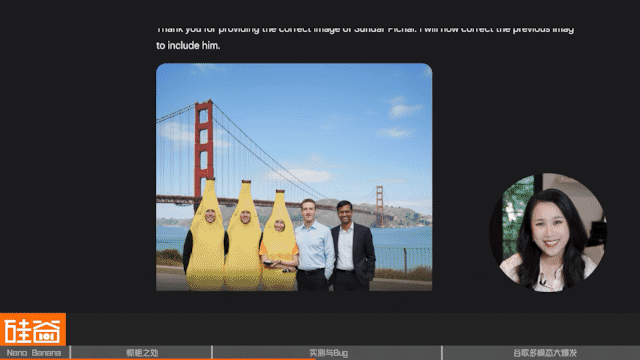
大家可以看出来,Nano Banana还是有很多bug的地方,这个我们稍后来说,但一般的合影需求,其实做得还是非常丝滑,非常出神入化。
比起娱乐、玩梗,其实更重要的是,多图融合能力现在已经显现出一种专业化替代的能力。
比如,有网友一次性输入了包括模特照片、产品、布景元素在内的十几张图片,让Nano Banana进行融合设计。最后的效果令人惊艳,几乎可以媲美、甚至超越广告设计公司。

而对于服装品牌们来说,Nano Banana几乎可以帮忙省去他们以后找模特拍产品图的工作。比如让Tylor Swift换身西装,只需上传一张衣服的平面照片就能搞定。

甚至还可以调整各种姿势、光影,连续生成各种角度、各种姿势的模特上身效果。
此外,拥有了“世界知识”的Nano Banana对抽象指令的理解能力也迎来了大幅跃升。
比如网友们随手画的一个简笔画,它就能准确地结合上传的人物图片进行姿势改变与创意设计。让奥特曼给你表演鞍马,一张图就能搞定。

再比如,在平面地图上随便画一根线,它就能给你展示从这根线的视角能看到什么样的实际风景。
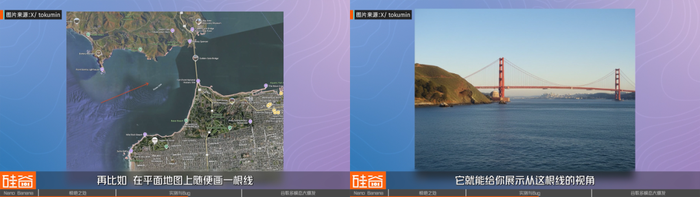
此外,官方介绍中的多轮对话式编辑和风格混配能力也并没有夸大其词。
比如把它用于室内设计和绘图渲染,或者让它用不同的花朵纹理给我设计一个新衣服等等。
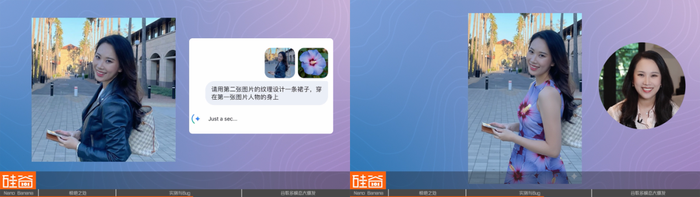
针对目前Nano Banana所展现出来的能力,Nathan表示,在某种程度上来说我们对图片的编辑能力已经开始达到了文字的类似水平。
Nathan Wang
硅谷101特邀研究员
Agent资深开发者:
它现在实现的功能相当我们在文字的这个阶段,你把其中一段话划出来,说你帮我改一下,或者这段话的语义不对,你帮我重新描述一下。现在它能够在图片上做到和文字编辑一样的效果,比如说把某个窗帘的颜色换成红色、换成蓝色,或者把物件给去掉,从一个图片中加这个物件,就很像我们在编辑文字式的,去在很细微、细枝末节的地方进行一定程度的优化和改变。
我觉得它是真正地在多模态的模型中做到了单一的语言模型可以达到的效果,这一点是很大的一个突破。
但其实,我们以上展示都还只是Nano Banana能力的冰山一角。自发布这几天来,网友们还正在不断挖出Nano Banana的各种玩法。

比如已经火爆全网的”手办模型”,我也忍不住上手制作了一个,效果真的是非常可爱。
除了“手办”等静态操作之外,另外一个爆火的趋势是将Nano Banana的能力跟其他平台结合,创作出效果惊艳的视频。
比如有人把Nano Banana和Seedance、 Kling结合使用,实现了让梵高、蒙娜丽莎从油画里走出来变成真人坐在中央公园聊天,有人使用Nano Banana和Seedance仅用不到两小时就做出一个动画短片,有人使用Nano Banana跟Weavy制作出细节满满的3D产品介绍等等。

那么,跟其他模型相比,Nano Banana的能力是不是真的要强大很多呢?我们自己也进行了几个简单的测试。
同样改变照片背景的指令。这是GPT-5的,人物几乎变了样。

这是FLUX的。人物倒是抠出来了,但是头发少了一块,人像是被贴上去的。

而到了让照片融合进行合影的指令,GPT不仅不能一次性理解并完成我的指令,生成出来的照片也完全不可用。不仅像贴上去的,甚至我这个人都变样了。

同样的Prompt在GPT上试了一下创建手办,人物比例、五官、背景等细节也都出现了不同程度的瑕疵。
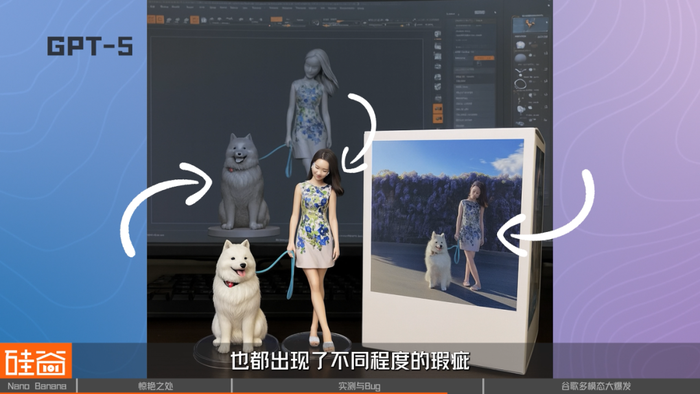
对比使用下来最大的感受是,目前在生成速度上其他模型不仅比Nano Banana慢了几倍,效果和输出稳定性方面也逊色不少。
当然,Nano Banana目前也并非没有翻车的时候。首先,在中文能力方面,Nano Banana依然没有出现质的突破。生成的图片依然存在文字乱码、乱读的现象。
对编辑指令的理解和执行也会出现偏差,比如我在要求对这个“手办”加上一双腿时它直接加到了盒子上,顺带着背景里的图片也不翼而飞。

还在多轮对话编辑中,它在面对复杂指令时可能突然就凌乱了。比如我在前文对话中想继续让它尝试多图融合,生成一张马斯克、扎克伯格、皮柴一起围观我怀里猩猩宝宝的照片。不仅人物比例和表情及其不协调,就连我这个照片主体变了一个人。
除此之外,网友对它不满意的地方还有图片分辨率不高、对提示词的审查太严格、艺术性和审美上比不上Midjourney、Imagen等等。
但总体来说,大家对于Nano Banana评价主要还是以积极、正面为主,几乎都认为这是文生图的又一里程碑。
03 五条主线谷歌的多模态生态大爆发
如果把Nano Banana放在更长的时间线上来看,你会发现,这并不是谷歌的一次“偶然爆发”。
事实上,在过去的一年多时间里,谷歌几乎用一种“密集轰炸”的节奏,把多模态产品一口气推到了前台。各种模型、各种迭代甚至可以用眼花缭乱来形容。
目前谷歌到底有哪些多模态产品线呢?我们来跟你一起理一理。
谷歌的多模态产品目前已经基本形成了一个完整的矩阵,它们大致可以分成五条主线。
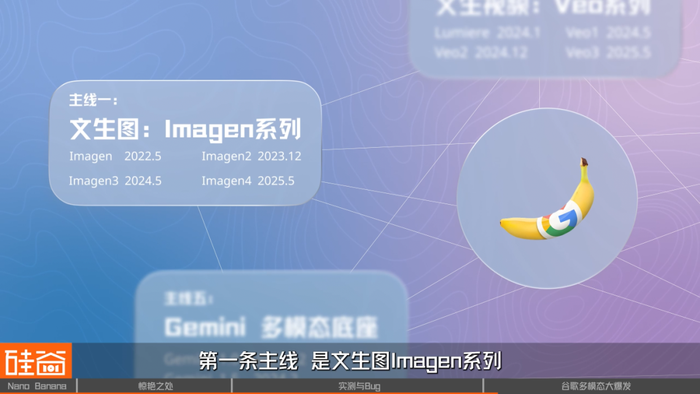
第一条主线,是文生图Imagen系列。
Imagen系列最早可以追溯到2022年5月,当时Google Research首次提出这一文生图模型。它的特点是结合大语言模型理解提示,再用扩散模型生成图像,在当时就被认为是超越DALL·E 2的新一代方案。不过因为安全和版权风险,Imagen一开始并没有开放给公众使用。直到2024年I/O大会,谷歌才正式推出Imagen 3,真正走向产品化。到2025年5月,Imagen 4发布,进一步强化了光影表现和细节质量,朝着“接近真实摄影”的方向迈进。
第二条主线,是文生视频的Veo系列。
2024年1月,谷歌研究院首次发布了Lumiere,用“时空一致性扩散”的方式直接生成整段视频,让动作和背景更加连贯自然。随后在2024年5月,I/O大会上正式亮相Veo 1,可以生成1080p高清视频。到了同年12月,Veo 2升级至4K,并首次接入Vertex AI平台。而在2025年5月I/O,谷歌再次亮相 Veo 3,不仅能生成视频,还能同步生成音乐和旁白,把文生视频真正推进到影视级创作的阶段。

第三条主线,是Genie系列,也就是“交互世界生成”,也被称为“世界模型”。
和文生视频的模型不同,Genie的目标不是做一段“看”的视频,而是直接生成一个“能玩”的虚拟世界。
Genie 1于2024年初首次亮相,作为第一个能够根据图像生成可玩2D游戏环境的模型,它展示了AI创造互动世界的潜力。紧随其后,Genie 2在2024年底发布,在一代基础上取得了巨大进步,它能生成更长、更复杂的3D互动世界,将AI生成的虚拟环境从二维平面扩展到了三维空间。
而最新的Genie 3在今年的8月5日推出,能力再次提升到了一个新高度,能够从文本或图像提示生成动态、可导航的3D世界,并首次支持实时交互和“提示性世界事件”,允许用户在生成环境中实时修改物体或天气,使其成为了一个真正意义上的“世界模型”。

换句话说,它不仅能帮你生成一段画面,还能让你能真正地“走进去”,去玩、去体验。
这让Genie成为了谷歌多模态矩阵里一个特别的分支:它不是单纯的视频生成,而是文生视频和虚拟交互的结合,预示着谷歌的多模态探索正在触碰“沉浸式体验”和“虚拟世界构建”的边界。
第四条主线,是面向创作者的工具集。
2024年5月,谷歌在I/O上同时推出了ImageFX和VideoFX,让用户可以直接在Labs中体验文生图与文生视频。到了2025年5月,谷歌又发布了Flow,这是一个专为影视叙事设计的工具,把Veo和Imagen的能力整合到分镜、镜头、叙事风格的工作流里。
最后一条主线,就是Gemini多模态底座。
Gemini是谷歌的通用多模态基础模型,是整个系统的“大脑”。它的核心能力在于理解、推理和处理各种信息,包括文本、图像、音频、视频等。Gemini扮演着一个通用智能体的角色,为其他更专业的模型提供强大的基础支持和世界知识。

2023年底,Gemini 1.0发布,确立了Ultra、Pro、Nano三个不同尺寸的模型家族形态。
2024年2月,Gemini 1.5发布,带来了革命性的进步,尤其是其突破性的长上下文窗口,让它能一次性处理海量的文本、代码、图像甚至视频,这让模型在理解复杂、冗长的文档或视频方面有了前所未有的能力。
2025年2月,Gemini 2.0系列登场,推出了Flash和Flash-Lite,能够更好地应对需要低延迟和大规模部署的应用场景。
2025年8月,Gemini 2.5 Flash Image也就是大家熟知的Nano Banana正式现身,把“AI修图”直接变成了人人可用的体验。
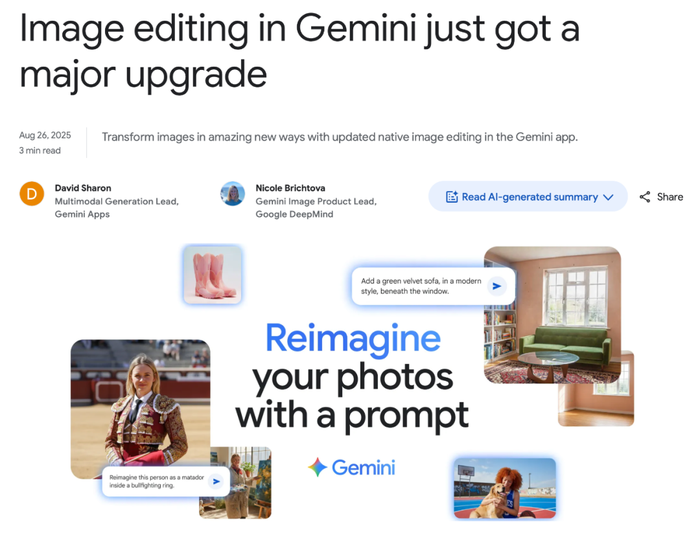
盘点下来你会发现,谷歌的多模态战略已经逐渐清晰成型:文生图的Imagen ,文生视频的Veo,探索交互世界的Genie,再通过Flow、ImageFX、VideoFX把这些能力嵌进创作工作流,而背后的支撑,是快速迭代的多模态底座Gemini。
在采访中Nathan谈到,谷歌所拥有的非常好的人才、基建和数据底座,是它在当前激烈的大模型竞争中的优势所在。在这看似复杂、庞大的产品线背后,谷歌其实也有着比较清晰的产品路线。
Nathan Wang
硅谷101特邀研究员
Agent资深开发者:
它每一次发不同的模型背后还是有着消费场景,或者是一定的用户案例,其实是针对不同的用户画像,因为大家在产品第一件事就是要去了解你的客户人群是谁,你才会去做产品,而不是说做了产品再去找客户人群。
所以在我看来谷歌的产品主线,还是根据客户人群、应用场景去开发和迭代它的模型和产品,思路其实是比较清晰的。
与此同时,谷歌也正在渐进式地朝着“大而全”的智能体方向推进。
张宋扬
亚马逊AGI部门Applied Sci:
现在很多大公司都希望做一个大而全的模型,能够支持不同的模态,是一个端到端的生成模型,包括语音、包括图片、包括视频、包括文字甚至包括代码,都希望做一个大而全的,因为这应该更符合大家对智能的认知。
但这是一个很大的框架,但在这个框架之下,我们可能需要针对每一种任务去进行研究,比如先研究怎么去生成图片,再怎么生成视频。所以你会发现,它们的模型是不同的团队在做,它们得先把某一个任务先突破了然后发布了一个产品,然后另外一个突破了再发一个产品。但我相信或者作为用户的角度,我们肯定也是希望它能够把这些模型融合在一起,这样使用界面也更简洁。
对于未来谷歌多模态的发展,大家目前普遍猜测,谷歌或许会把更多的模型能力向Gemini融合,进而面向普通用户打造一个的多模态的超级流量入口。
而如Imagen、Veo、Genie等模型未来则将继续向纵深发展,主要为专业级的开发提供服务。
图源:ai.google
从Nano Banana,到一整套多模态矩阵,我们看到了谷歌过去一年多的加速爆发。在这场生成式AI的竞赛里,谷歌曾被质疑掉队。但现在,无论是图像、视频,还是虚拟世界和创作工作流,谷歌几乎把所有环节都重新补齐。
这种“连环拳”式的产品发布,似乎在向外界释放出一个信号:谷歌不只是在追赶,而是在试图用一个完整矩阵去重新定义生成式AI的边界。
但问题是,这样的爆发能不能真正转化为市场优势?在这场速度与创新的较量中,Nano Banana又能领先多久呢?
欢迎在评论区告诉我们,你觉得谷歌的这波多模态大爆发如何,Nano Banana到底好不好用?







